


Bloom, ce modèle que tout le monde déteste...
Un modèle déchu, soumis à de nombreuses critiques, mais qui possède une architecture qui lui permettrait probablement d'être State-of-the-Art.


C’est dans un contexte où les modèles de langue se succèdent avec une cadence effrénée, où les enjeux financiers de ceux qui les créent sont astronomiques, et où la législation autour de l'open-sourcing de ces modèles est aujourd’hui disputée qu’il est crucial d'évaluer objectivement les différences entre modèles open-sources et modèles propriétaires. Ces initiatives pleinement ouvertes ont la capacité de faire aussi bien, et j’en suis persuadé, même mieux que les initiatives fermées ou semi-ouvertes des grands acteurs de l’IA.
Dans ce post j’interroge les sources réelles des différences de performances entre Bloom, la série de modèles la plus transparente à ce jour, et ses concurrents dits “open-weight”, notamment dans sa version 7b qui est la taille privilégiée actuellement par les acteurs du domaine.
Un modèle obsolète ?
C’est ce que j’entends constamment autour de moi, dans des discussions entre experts (qu’ils soient chercheurs, ingénieurs ou aficionados du ML), la moindre discussion autour de ce modèle, la moindre mention d’un projet qui utiliserait ce dernier conduit à une réaction presque viscérale de dégoût de l’interlocuteur.
“On l’a essayé en production, ça donnait vraiment des résultats pourris”
“Bloom c’est vraiment dépassé, c’est clairement pas SOTA”
Si on se doit de saluer à bien des égards l’initiative unique menée par HuggingFace dans son projet BigScience, pour son approche open-source, open-science et open-data, ainsi que son attachement à la représentation de 46 langues (+13 de programmation); il faut admettre que les retours individuels et résultats sur les benchmarks académiques (avec tous les défauts qu’ils possèdent) sont décevants face à des Falcon/Llama et dernièrement Mistral.
Malgré la sortie de Llama en février 2023, des initiatives finlandaises ont cependant décidé de se lancer dans la continuation de l’entrainement de Bloom (Bluumi), mais aussi de ré-apprendre carrément “from scratch” des modèles autour de cette architecture (voir Poro-34B). Pour beaucoup cela semble être une véritable hérésie.
Mais la véritable question demeure, a t-on progressé de manière significative sur les architectures transformer pour justifier cette réaction ? Quelle est la véritable cause de cette sous-performance de Bloom ? Dans ce post, j’essaie d’introduire des éléments de réflexions.
Un modèle “mal-conçu” ?
“Nan mais y a eu pleins d’améliorations architecturales depuis Bloom, les Rotary Embeddings, etc… ”
L’architecture ? Les données ? La méthode d’entrainement ? S’il y a bien une tâche pour laquelle la nature en partie expérimentale du deep learning, de par son coût important, ne permet pas de trancher par la classique “étude d’ablation”, c’est bien le pré-entrainement des modèles.
Alors dans cet engouement actuel autour des modèles à 7 milliards de paramètres, les fameux “7b” je me suis penché sur les différences principales (quand documentées) entre Bloom, Falcon, Llama2 et Mistral.
Bloom et son architecture
Sur le plan architectural, l’ensemble des modèles se targue d’une architecture transformer-decoder, et on peut voir qu’à bien des égards peu d’aspects notoirement distincts se détachent de ce point de vue pour expliquer la faible performance de Bloom.
Il est finalement tout à fait comparable aux autres modèles à l’exception de deux points: Un encodage positionnel “Alibi” et un tokenizer d’une taille bien plus importante.
Les particularités de Bloom
1- Alibi, l’origine des tous les maux ?
Les positional embeddings Rotary (RoPE) et Alibi sont deux méthodes d’encoding de positions apparues en 2021. Dans son papier, Alibi se compare à RoPE sur l’extrapolation à des séquences plus longues que celles vu au cours du pré-entrainement et démontre une supériorité “out-of-the-box”sur ce point:
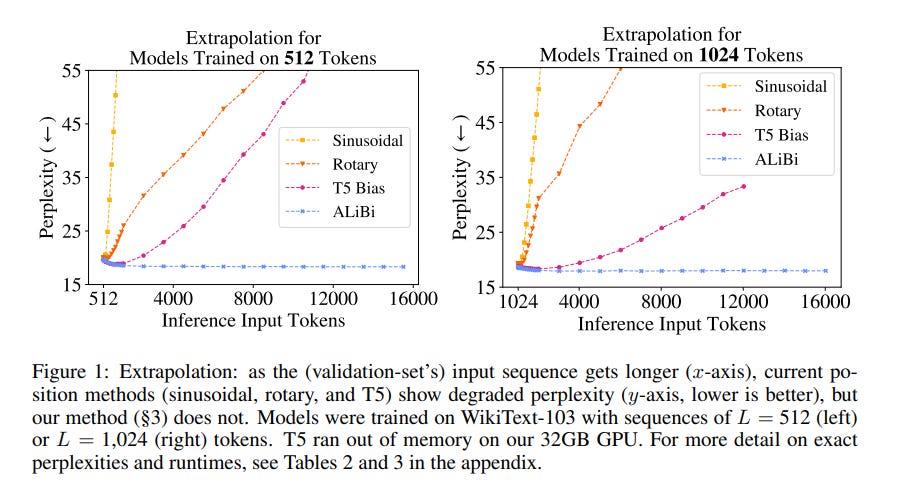
Si l’on s’en réfère à l’article de la famille de modèles Falcon, dont le code d’implémentation prévoit d’ailleurs la possibilité d’utiliser Alibi, on peut voir les résultats des expériences réalisées pour motiver le choix de RoPE:

On peut y lire que l’avantage observé n’est peut-être pas significatif pour le 1B et encore moins clair avec l’augmentation de la taille du modèle.
“At the 1B scale, we find a likely advantage to using RoPE over ALiBi; however, that advantage diminishes at the 3B scale, and is insufficient to conclude clearly. One remaining advantage of ALiBi is its compute overhead: it is significantly cheaper to compute than RoPE; however, with custom Triton kernels (Section 5.3.2) we are able to mitigate that overhead.”
Le choix de l’équipe se conclut donc par un choix par défaut:
“In-line with other popular large-scale models, we adopt rotary positionnal embeddings, and use custom kernels to mitigate the overhead.”
Enfin, cette étude de comparaison avait aussi été menée par le groupe de travail sur l’architecture de Bloom, qui conclut à l’utilisation d’Alibi justement pour ses capacités de généralisation à des contextes plus larges en zéro-shot.
2 - Un tokenizer trop grand?
Si l’impact de la taille du tokenizer a effectivement un impact lors de l’apprentissage du modèle, la taille du tokenizer de Bloom s’aligne sur les tailles des tokenizers d’autres modèles multilingues tels que Palm et son vocabulaire de 256k tokens. De telles tailles semblent nécessaires pour bien représenter l’ensemble des langues.
Mistral et Llama2 des révolutions architecturales ?
3 - La fonction d’activation SwiGlu
Établie pour la première fois en 2020 dans un papier de Google, cette fonction d’activation conduit à de légère amélioration de performances en perplexité sur un encoder-decoder:

Ainsi que sur les benchmarks de GLUE et de SuperGLUE, passant d’un score moyen de 84.20 à 84.36 et de 73.95 à 74.56 respectivement.
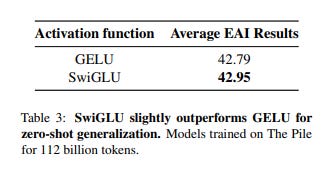
Cette fonction d’activation avait aussi été prise en considération par le groupe de travail sur l’architecture de Bloom qui revient sur décision initiale, recommandant SwiGlu pour les prochains modèles en lui admettant un léger avantage:
4- Root Mean Square Layer Normalization (RMSNorm)
Le papier de RMSNorm est un papier de 2019, montrant que cette nouvelle méthode de normalisation permet des gains significatifs de vitesse de calcul avec des performances comparables à la classique LayerNorm dans le cadre d’utilisation de RNNs.
“Extensive experiments on several tasks using diverse network architectures show that RMSNorm achieves comparable performance against LayerNorm but reduces the running time by 7%∼64% on different models.”
5- Le Grouped Query Attention
Qui fait parler de lui depuis les modèles Mistral et les Llama2 34B et 70B. C’est un papier de 2020 issu de Google Research, qui montre qu’il est notamment possible de diminuer le nombre de matrices de query et de les associer à plusieurs têtes d’attention avec peu ou pas de pertes de performances, mais une diminution du nombre de paramètres et une meilleure efficience calculatoire.
Dans ce papier, on ajoute d’ailleurs ce mécanisme en fusionnant les queries d’un modèle T5 pré-entraîné et en continuant son pré-entrainement. Ce mécanisme est donc en pratique adaptable à n’importe quel transformer.
Il est vrai cependant que ce gain de paramètres a permis à Mistral d’augmenter les tailles intermédiaires de ses couches feedforward par rapport à Llama2.
Une question d’entrainement ?
Bloom, un modèle surtout sous-entrainé, même dans sa version 7b.
Si Bloom utilise l’optimizer Adam présent dans la librairie DeepSpeed Megatron (AdamW y étant indisponible encore à ce jour), il semblerait malhonnête d’imputer l’origine des écarts de performances à ce choix. Tous ces modèles, à l’exception de Mistral (dont aucune information n’est connue sur ce point), utilisent des optimizers similaires, avec stratégie similaire: un warmup et un scheduling cosine.
La différence qui frappe majoritairement dans ce tableau c’est la différence de nombre de tokens vu pendant l’entrainement des modèles. C’est d’ailleurs assez prédictifs de leurs classements en termes de performances.
On observe ainsi que Bloom-7b est entraîné sur entre 5 et 6 fois moins de tokens que ses rivaux, et même entre 15 fois et 18 fois moins de tokens anglais, langue majoritairement utilisée aujourd’hui dans l’évaluation des modèles.
Les Chinchillas Laws, un tournant stratégique.
Entre la sortie de Bloom et celles de ses successeurs, un papier de DeepMind a vu le jour qui a en partie changé la course à la taille des modèles initialement lancée, celui des fameuses Chinchillas Laws (Qui montrent par ailleurs, que la plupart des modèles de l’époque étaient sous-entraînés).
Ce qu’elles disent et ne disent pas
Ce que montre ce papier, c’est qu’il existe en réalité des triplets optimaux (budget computationnel, taille de modèle, taille de jeu de données d’entrainement). Et qu’à un de ces paramètres fixés correspond les deux autres.
Si l’on imagine partir d’un modèle “compute-optimal” (c’est-à-dire un des triplet optimaux), et que l’on décide de continuer son entrainement sur de nouvelles données (on fixe la taille du modèle et on augmente le budget computationnel et la taille du jeu de données). Si l’on suppose que la quantité de données n’est pas le facteur limitant de ce nouvel entrainement, ce que disent les lois Chinchillas c’est qu’on aurait dû utiliser initialement un modèle plus grand afin d’obtenir une meilleure perplexité. Autrement dit, les lois Chinchillas ne disent pas que le modèle ne s’améliore plus en continuant son entrainement au-delà, il n’est juste plus la meilleure solution existante avec ce budget.
La règle s’est par la suite traduite par “Il faut 20 tokens de texte par paramètre de modèle”. D’une part cela est sans doute vrai à nature de jeu de données fixé (quid de jeux de données multilingues, plus simples/plus complexes?), d’autre part on parle là encore de modèles “constitutionnellement-optimaux”.
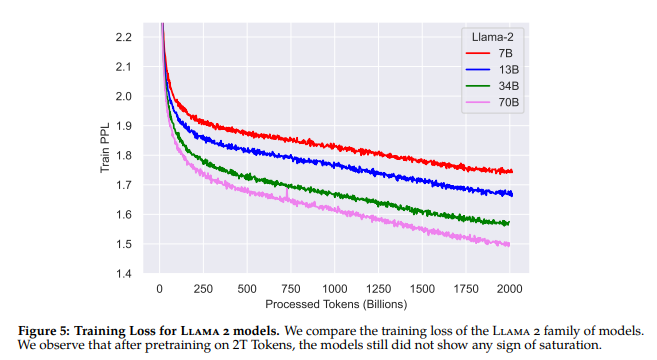
Les courbes d’entrainement de Llama2 permettent de bien comprendre cette notion, pour un modèle de 7B paramètres, le triplet “compute-optimal” est situé à 7*20=140B tokens. Sur les courbes de perplexité, on voit bien que le modèle 7B continue à converger vers des niveaux de perplexités plus bas bien après cette limite, et qu’à l’issue des 2000B on est toujours pas à saturation.
Conclusion
J’espère que cet article vous a plu et qu’il vous aura peut-être apporté des clés de compréhensions supplémentaire sur les différences et similarités entre le modèle Bloom et ses successeurs. Enfin j’espère qu’il vous éclairera sur ma conviction dans la force des initiatives open-source, open-data et open-science dans leurs capacités à développer des modèles concurrentiels face aux acteurs majeurs de l’IA.